Muntasir Hossain

I am a data scientist with expertise in big data analysis, machine learning and deep learning, computational modelling, generative AI, large language models (LLMs), natural language processing (NLP), and machine learning operations (MLOps). I have a proven track record of delivering impactful results in diverse areas such as technology, cybersecurity and energy. I have practical experience in developing end-to-end machine learning workflow including data preprocessing, model training at scale and model evaluation, deploying in production and model monitoring with data pipeline automation.
View my LinkedIn profile
Selected projects in data science, machine learning (ML), deep learning, generative AI, NLP and computer vision.
Multi-step energy usage forecasting with CNN-LSTM neural networks
This project implements a multi-step time-series forecasting model using a hybrid CNN-LSTM architecture. The 1D convolutional neural network (CNN) extracts local patterns (e.g., short-term fluctuations, trends) from the input sequence, while the LSTM network captures long-term temporal dependencies. Unlike recursive single-step prediction, the model performs direct multi-step forecasting (Seq2Seq), outputting am entire future sequence of values at once. Trained on historical energy data, the model forecasts weekly energy consumption over a consecutive 10-week horizon, achieving a Mean Absolute Percentage Error (MAPE) of 10% (equivalent to an overall accuracy of 90%). The results demonstrate robust performance for long-range forecasting, highlighting the effectiveness of combining CNNs for feature extraction and LSTMs for sequential modeling in energy demand prediction.
Figure: Actual and predicted energy usage over 10 weeks of time period.
MLOps with AWS: Train and deploy ML models at scale with automated pipelines
Develop an end-to-end machine learning (ML) workflow with automation for all the steps including data preprocessing, training models at scale with distributed computing (GPUs/CPUs), model evaluation, deploying in production, model monitoring and drift detection with Amazon SageMaker Pipeline - a purpose-built CI/CD service.
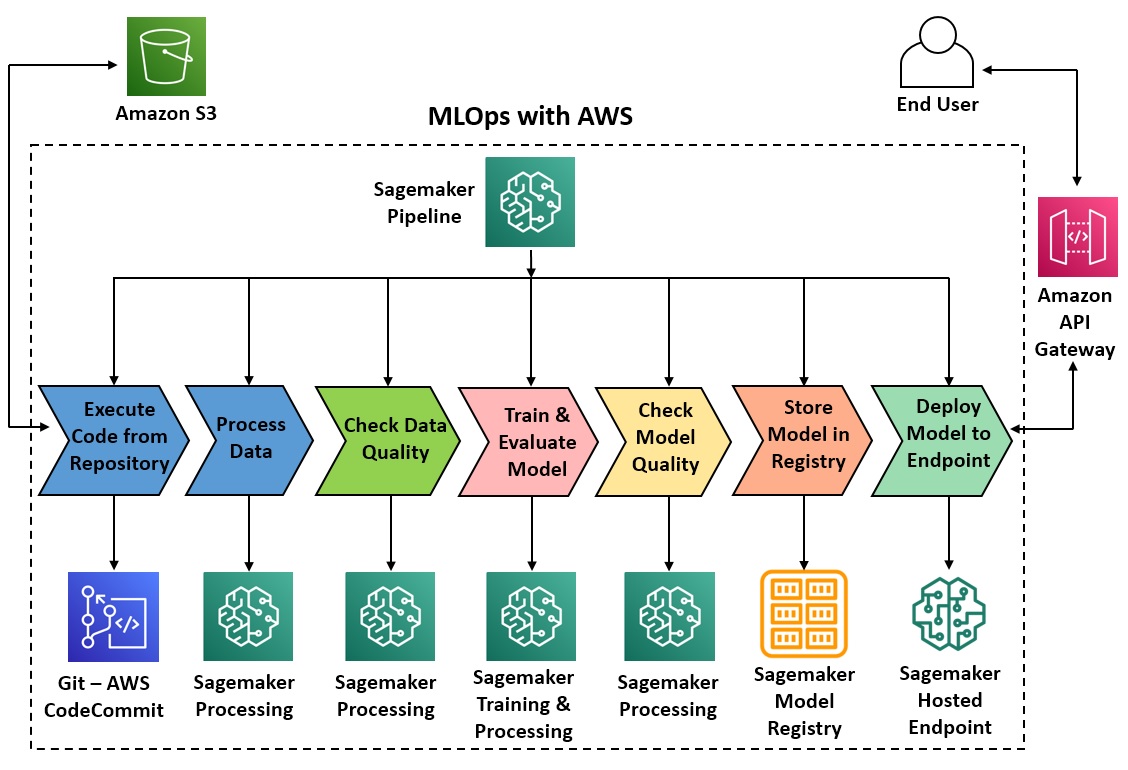 Figure: ML orchestration reference architecture with AWS
Figure: ML orchestration reference architecture with AWS
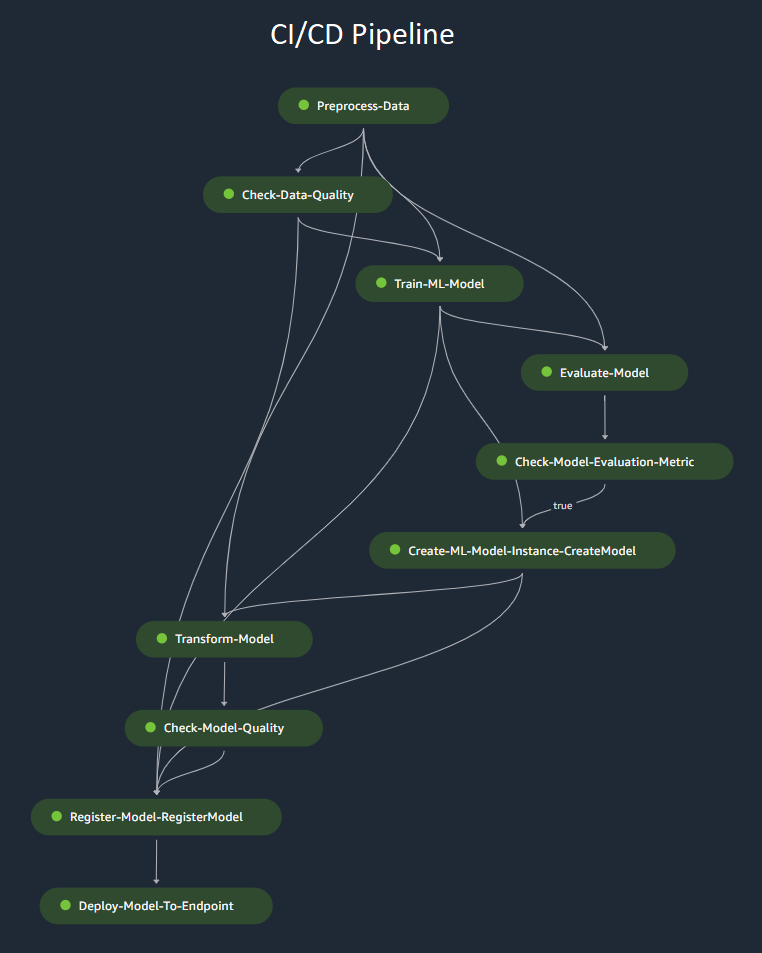 Figure: CI/CD pipeline with Amazon Sagemaker
Figure: CI/CD pipeline with Amazon Sagemaker
Analysing the global CO₂ emission: How did countries, regions and economic zones evolve over time?
The World Bank provides data for greenhouse gas emissions in million metric tons of CO₂ equivalent (Mt CO₂e) based on the AR5 global warming potential (GWP). It provides information on environmental impact at both national, regional and economic levels over the past six decades.
Global CO₂ emissions
Figure: Interactive visualization of global CO₂ emissions by country and year
Time sereis CO₂ emissions
Figure: Time sereis CO₂ emissions for selected countries
Population Growth
Figure: Population growth for selected countries
CO₂ emissions by income groups
Figure: Interactive visualization of CO₂ emissions for different income zones from 1970 to 2023
CO₂ emissions by geographic regions
Figure: Interactive visualization of CO₂ emissions for different geographic regions from 1970 to 2023
Some key insights from the data:
- Many countries (e.g. China, India) and regions show a clear upward trend in carbon dioxide emissions from 1960 to 2024. For instance, although the population of China increased from 0.82 billion in 1970 to only 1.41 billion in 2023, emission drastically increased from 909 Mt CO₂e to over 13000 Mt CO₂e, reflecting rapid industrialization. While the population of China and India in 2023 were nearly the same, the CO₂ emission from China was 4.5 fold to that of India.
- There is significant variation between countries. Highly industrialized or resource-rich nations (e.g., Saudi Arabia, United Arab Emirates) emit far more CO₂ than smaller or less industrialized countries (e.g., Aruba, Burundi).
- The data suggests a strong link between economic development and emissions growth. Countries experiencing rapid economic expansion (e.g., Vietnam, United Arab Emirates) show marked increases in emissions, while some developed countries (e.g., Germany, Austria, Belgium) have stabilized or slightly reduced their emissions in recent years, likely due to policy interventions or shifts to cleaner energy.
- While ‘High Income’ regions dominated the CO2 emissions pre-2020, the ‘Middle Income’ and ‘Upper Middle Income’ regions rapidly increased CO2 emissions after 2000, exceeding the emissions from ‘High Income’ regions.
Fine-tuning LLMs with Odds Ratio Preference Optimization (ORPO) and Quantized Low-Rank Adaptation (QLoRA)
ORPO (Odds Ratio Preference Optimization) is a single-stage fine-tuning method to align LLMs with human preferences efficiently while preserving general performance and avoiding multi-stage training. This method trains directly on human preference pairs (chosen, rejected) without a reward model or reinforcement learning (RL) loop, reducing training complexity and resource usage. However, fine-tuning an LLM (e.g. full fine-tuning) for a particular task can still be computationally intensive as it involves updating all the LLM model parameters. Parameter-efficient fine-tuning (PEFT) updates only a small subset of parameters, allowing LLM fine-tuning with limited resources. Here, I have fine-tuned the Mistral-7B-v0.3 foundation model with ORPO and QLoRA (a form of PEFT), by using NVIDIA L4 GPUs. In QLoRA, the pre-trained model weights are first quantized with 4-bit NormalFloat (NF4). The original model weights are frozen while trainable low-rank decomposition weight matrices are introduced and modified during the fine-tuning process, allowing for memory-efficient fine-tuning of the LLM without the need to retrain the entire model from scratch.
Check the model on Hugging Face hub!
Retrieval-Augmented Generation (RAG) with LLMs, embeddings, vector databases, and LangChain
RAG is a technique that combines a retriever and a generative LLM to deliver accurate responses to queries. It involves retrieving relevant information from a large corpus and then generating contextually appropriate responses to queries. Here, I used the open-source Llama 3 and Mistral v2 models and LangChain with GPU acceleration to perform generative question-answering (QA) with RAG.
Try my app below that uses the Llama 3/Mistral v2 models and FAISS vector store for RAG on your PDF documents!
Reinforcement Learning with Human Feedback (RLHF)
Reinforcement Learning with Human Feedback (RLHF) is a cutting-edge approach used to fine-tune Large Language Models (LLMs) to generate outputs that align more closely with human preferences and expectations. Here, I utilised RLHF to further fine-tune a Google Flan-T5 Large and generate less toxic content. The model was previously fine-tuned for generative summarisation with PEFT. A binary classifier model from Meta AI was used as the reward model to score and reward the LLM output based on the toxicity level. The LLM was fine-tuned with Proximal Policy Optimization (PPO) using those reward values. The iterative process for maximising cumulative rewards and fine-tuning with PPO enables detoxified LLM outputs. To ensure that the model does not deviate from generating content that is too far from the original LLM, KL-divergence was employed during the iterative training process.
Check the model on Hugging Face hub!
Computer Vision: Deploying YOLOv8 model at scale with Amazon Sagemaker Endpoints
YOLO (you only look once) is a state-of-the-art, real-time object detection and image segmentation model used in computer vision. The latest model YOLOv8 is known for its runtime efficiency as well as detection accuracy. To fully utilise its potential, deploying the model at scale is crucial. Here, a YOLOv8 model was hosted on the Amazon SageMaker endpoint and inference was run for input images/videos for object detection.
 Figure: Object detection with YOLOv8 model deployed to a real-time Amazon SageMaker endpoints.
Figure: Object detection with YOLOv8 model deployed to a real-time Amazon SageMaker endpoints.