Muntasir Hossain

I am a data scientist with expertise in big data analysis, machine learning (ML) and deep learning, computational modelling, predictive modelling, computer vision and generative AI. I have a proven track record of delivering impactful results in diverse areas such as energy, technology, and cybersecurity. I have practical experience in developing end-to-end machine learning workflow including data preprocessing, model training at scale and model evaluation, deploying in production and model monitoring with data pipeline automation.
View my LinkedIn profile
Selected projects in data science, machine learning, deep learning, and LLMs.
Neural Networks for Time-Series Forecasting
This project implements a multi-step time-series forecasting model using a hybrid CNN-LSTM architecture. The 1D convolutional neural network (CNN) extracts spatial features (e.g., local fluctuations) from the input sequence, while the LSTM network captures long-term temporal dependencies. Unlike recursive single-step prediction, the model performs direct multi-step forecasting (Seq2Seq), outputting am entire future sequence of values at once. Trained on historical energy data, the model forecasts weekly energy consumption over a consecutive 10-week horizon, achieving a Mean Absolute Percentage Error (MAPE) of 10% (equivalent to an overall accuracy of 90%). The results demonstrate robust performance for long-range forecasting, highlighting the effectiveness of combining CNNs for feature extraction and LSTMs for sequential modeling in energy demand prediction.
Figure 1: Actual and predicted energy usage over 10 weeks of time period.
Analysis & Interactive Visualisation of Global CO₂ Emissions
The World Bank provides greenhouse gas emissions data in million metric tons of CO₂ equivalent (Mt CO₂e), calculated using AR5 global warming potential (GWP). The dataset captures environmental impact at national, regional, and income-group levels over more than six decades.
Analytical approach
Time-series aggregation and normalisation across countries, regions, and income groups; comparative cohort analysis across geographic and economic classifications; and interactive filtering to support exploratory pattern detection and trend analysis.
Key insights
-
Several rapidly industrialising countries, including China, India, and Indonesia, exhibit sustained and substantial emissions growth between 1960 and 2024. For instance, while China’s population increased from 0.82 billion in 1970 to 1.41 billion in 2023 (72% growth), its emissions rose from 909 Mt CO₂e to over 13,000 Mt CO₂e, a 1,330% increase (approximately 14.3-fold). This divergence between population growth and emissions growth reflects the scale and intensity of industrial expansion. Despite near-equal population sizes in 2023, China’s emissions were approximately 4.5 times those of India (Figure 4).
-
Emissions levels display pronounced cross-country dispersion. Highly industrialised or resource-rich economies, such as Saudi Arabia and United Arab Emirates, record substantially higher emissions than smaller or less industrialised nations, including Aruba and Burundi.
-
The analysis suggests a strong association between economic expansion and emissions growth. Rapidly growing economies such as Vietnam, Saudi Arabia, and the United Arab Emirates show pronounced upward trajectories in CO₂ emissions. These increases may reflect different underlying drivers, ranging from coal-based electricity expansion and export-oriented manufacturing in Vietnam to oil extraction and refining, energy-intensive industries, and fossil-fuel-based electricity generation in the Gulf economies. In contrast, several advanced economies, including United Kingdom, Germany, Japan, Austria, and Belgium, demonstrate stabilisation or modest declines in recent years, consistent with structural energy transitions and policy interventions (Figure 4).
-
While ‘High Income’ regions accounted for the largest share of global emissions prior to 2020, ‘Middle Income’ and ‘Upper Middle Income’ regions experienced accelerated post-2000 growth, ultimately surpassing the contribution of ‘High Income’ regions (Figure 6).
-
Europe and North America dominated global CO₂ emissions during the final decades of the 20th century. By 2023, however, the East Asia & Pacific region had become the largest emitter, accounting for 46.6% of global emissions, compared with about 14% each from North America and Europe (Figure 6).
Time sereis CO₂ emissions
Figure 4: Time sereis CO₂ emissions for selected countries
CO₂ emissions by income groups
Figure 5: Interactive visualization of CO₂ emissions for different income zones from 1970 to 2023
CO₂ emissions by geographic regions
Figure 6: Interactive visualization of CO₂ emissions for different geographic regions from 1970 to 2023
End-to-End ML Pipelines and Deployment at Scale
Develop an end-to-end machine learning (ML) workflow with automation for all the steps including data preprocessing, training models at scale with distributed computing (GPUs/CPUs), model evaluation, deploying in production, model monitoring and drift detection with Amazon SageMaker Pipeline - a purpose-built CI/CD service.
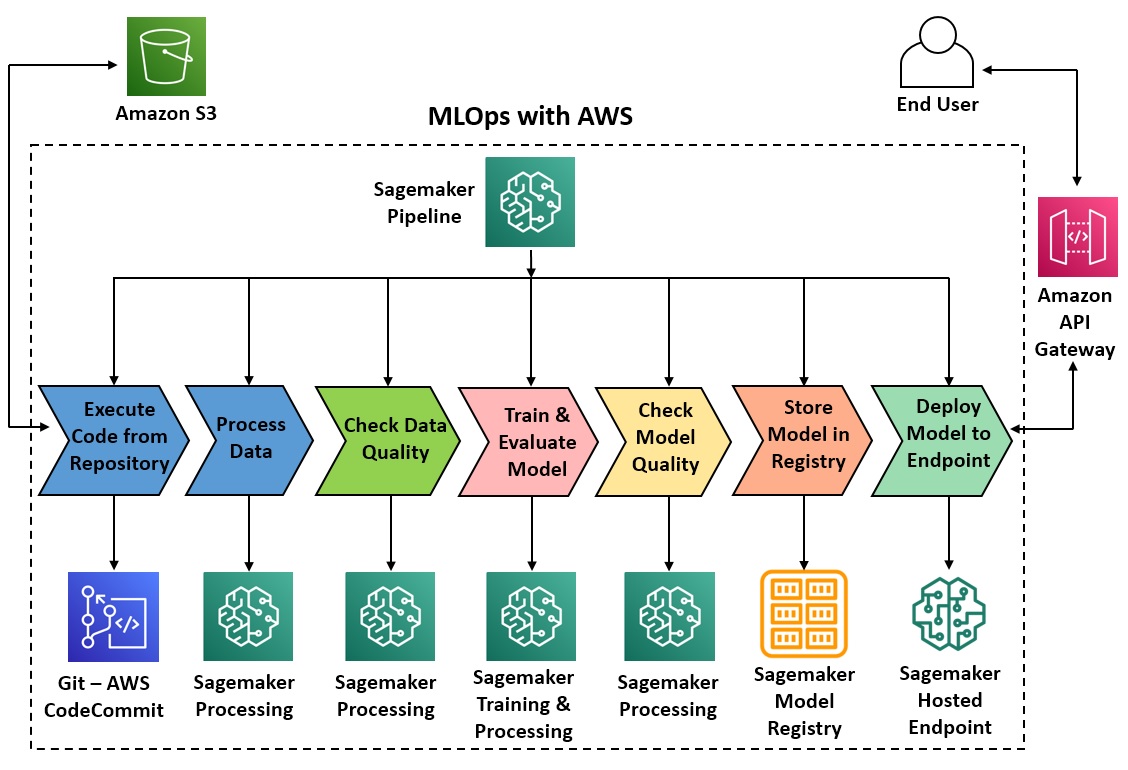 Figure 2: ML orchestration reference architecture with AWS
Figure 2: ML orchestration reference architecture with AWS
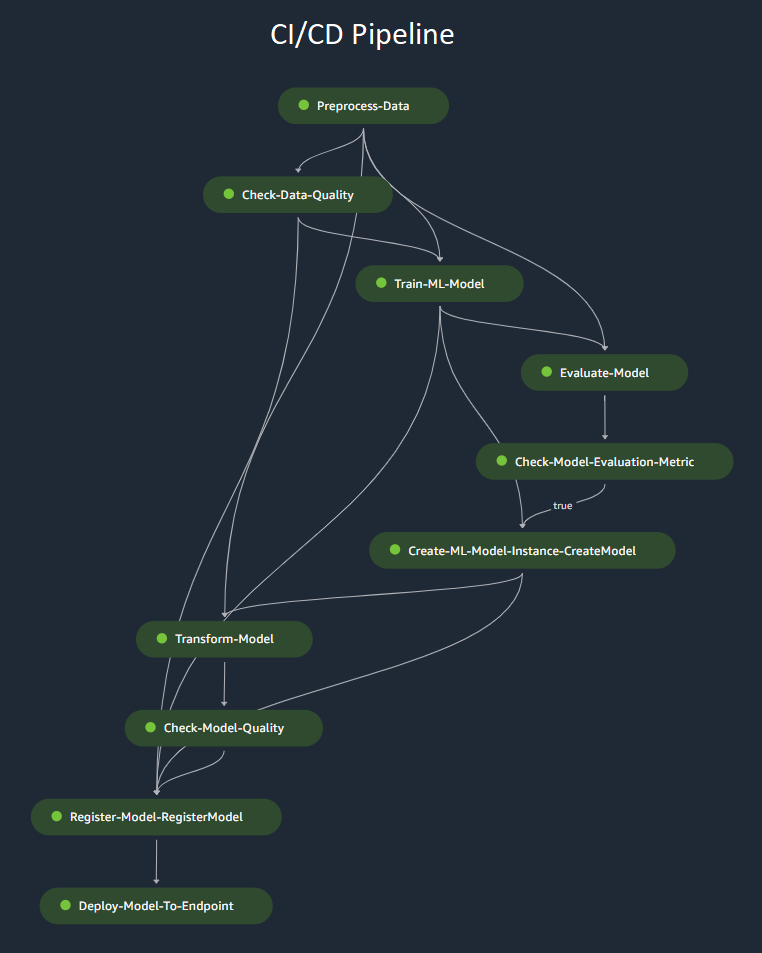 Figure 3: CI/CD pipeline with Amazon Sagemaker
Figure 3: CI/CD pipeline with Amazon Sagemaker
Multi-Agent Workflow for Analytical Reporting
This project demonstrates an automated workflow for analytical report generation. A coordinated set of AI agents decomposes complex topics into structured tasks, retrieves relevant information from multiple sources by using tools (web search, archive, and Wikipedia extractor), and synthesises findings into a coherent report. The system supports efficient information gathering, structured analysis, and clear communication of insights, reflecting a practical approach to scaling analytical reporting. Please try the agentic app below (deployed over the cloud using Docker):
Fine-tuning LLMs with ORPO & QLoRA
ORPO (Odds Ratio Preference Optimization) is a single-stage fine-tuning method to align LLMs with human preferences efficiently while preserving general performance and avoiding multi-stage training. This method trains directly on human preference pairs (chosen, rejected) without a reward model or reinforcement learning (RL) loop, reducing training complexity and resource usage. However, fine-tuning an LLM (e.g. full fine-tuning) for a particular task can still be computationally intensive as it involves updating all the LLM model parameters. Parameter-efficient fine-tuning (PEFT) updates only a small subset of parameters, allowing LLM fine-tuning with limited resources. Here, I have fine-tuned the Mistral-7B-v0.3 foundation model with ORPO and QLoRA (a form of PEFT), by using NVIDIA L4 GPUs. In QLoRA, the pre-trained model weights are first quantized with 4-bit NormalFloat (NF4). The original model weights are frozen while trainable low-rank decomposition weight matrices are introduced and modified during the fine-tuning process, allowing for memory-efficient fine-tuning of the LLM without the need to retrain the entire model from scratch.
Check the model on Hugging Face hub!
-